Model repository & versioning
Centrally store, version and govern models across teams and projects.
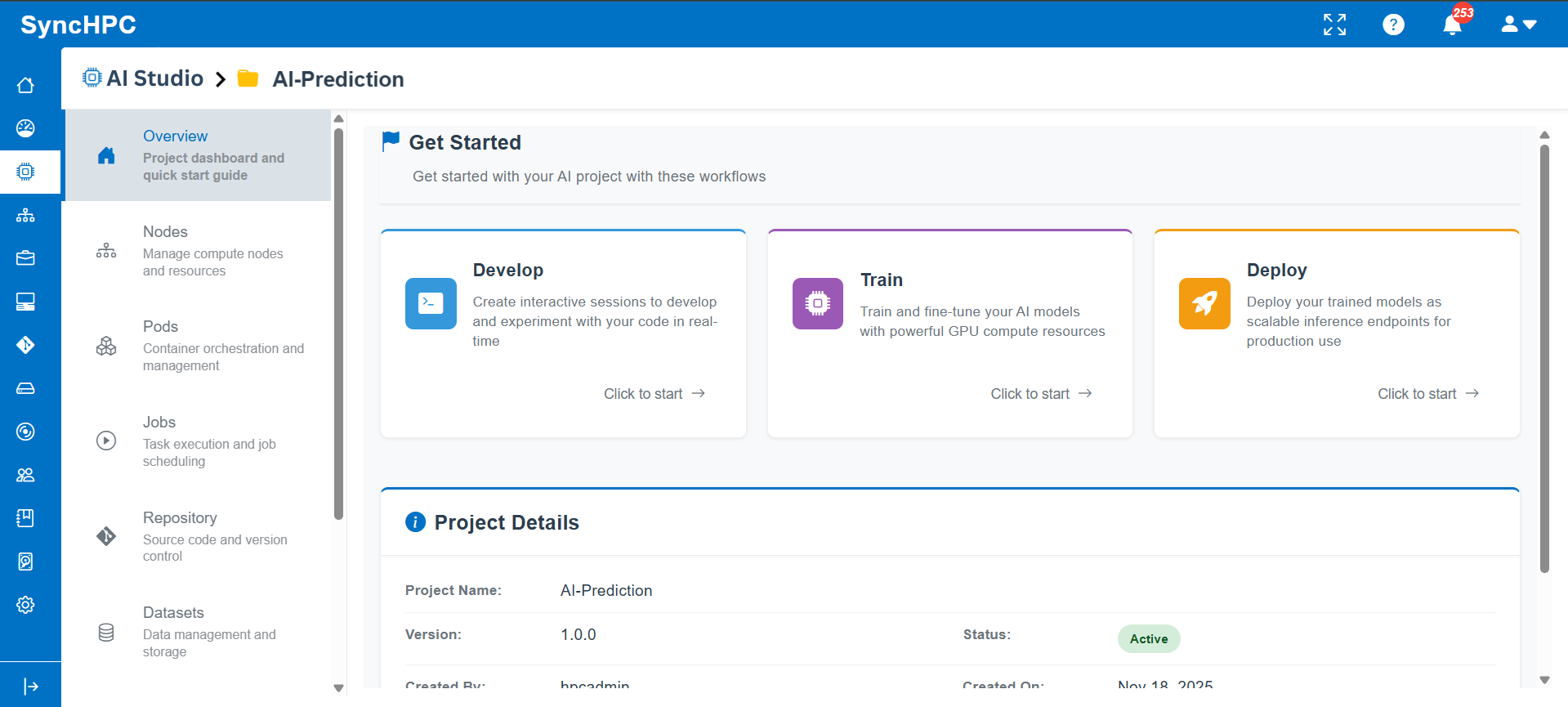
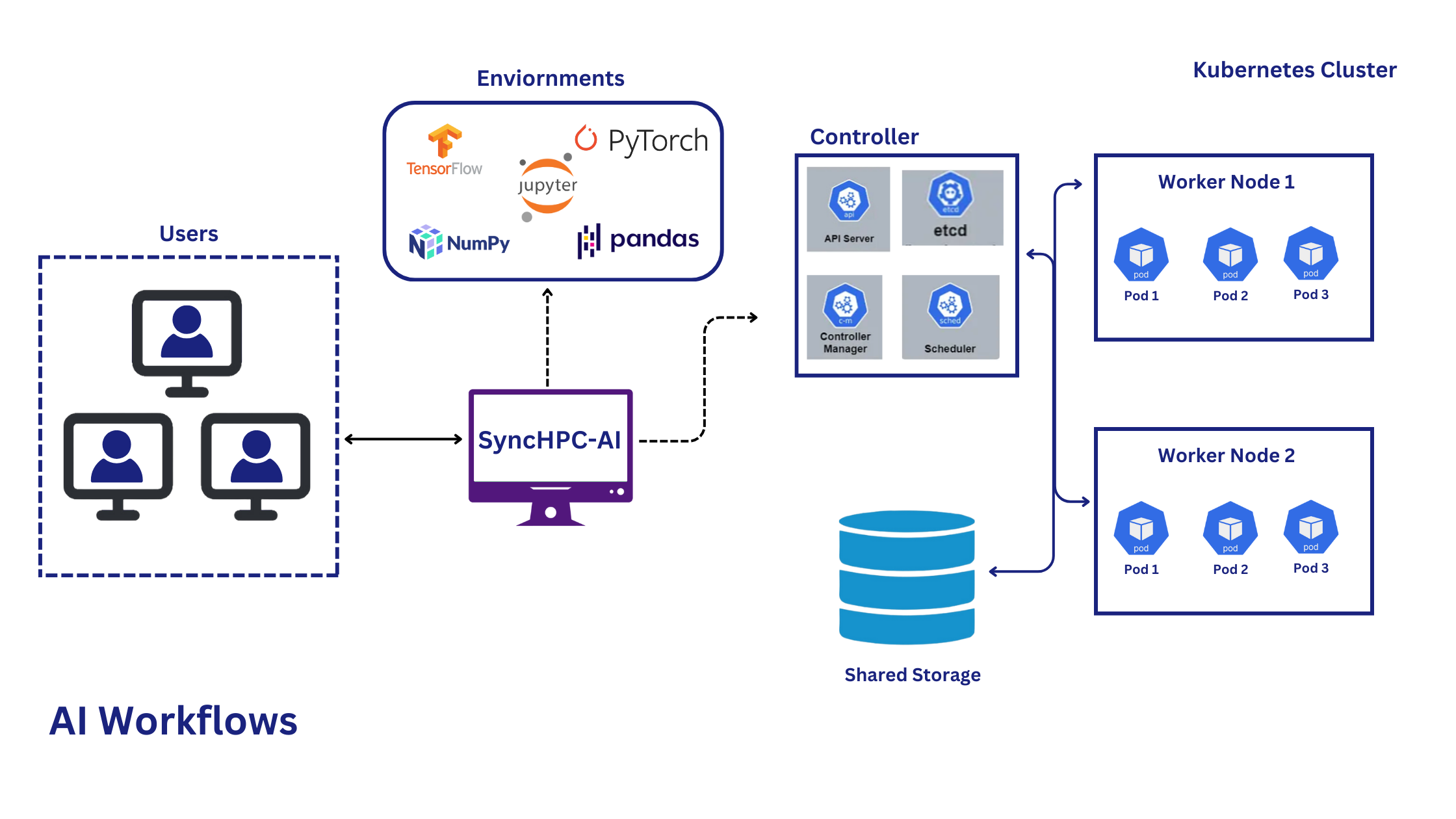
Interactive AI workflows
Spin up a Jupyter Notebook or terminal in seconds, backed by GPU compute.
Scalable inferencing
Deploy models for distributed, production-grade inference that scales on demand.
Kubernetes-native
Use kubectl commands and Helm charts to deploy the exact PODs you need.
High-performance GPUs
Run on the latest accelerators, including NVIDIA H100 and H200.
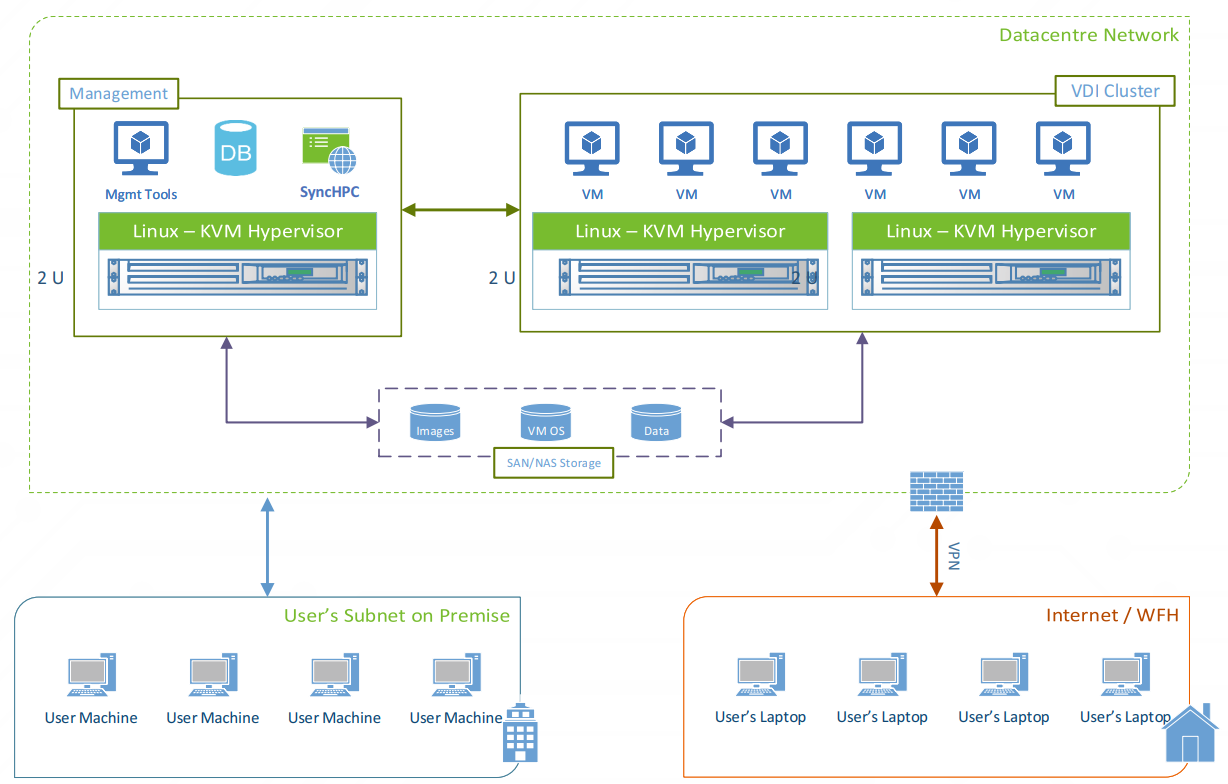
Cost-effective AI labs
Per-user resource allocation and monitoring keep utilization and spend in check.